Back to all members...
Angelos Filos
PhD, started 2018

Angelos is a DPhil student in the Department of Computer Science at the University of Oxford, where he works in the Applied and Theoretical Machine Learning group (OATML) under the supervision of Yarin Gal. His research interests span multi-agent systems, meta-learning and reinforcement learning. He obtained an undergraduate and master’s degree from the Department of Electrical and Electronic Engineering at Imperial College London. He also contracts with J.P. Morgan Artificial Intelligence Research group, working on generative models, distributional reinforcement learning and inverse reinforcement learning.
News items mentioning Angelos Filos • Publications while at OATML • Reproducibility and Code • Blog Posts
News items mentioning Angelos Filos:

NeurIPS 2021
11 Oct 2021
Thirteen papers with OATML members accepted to NeurIPS 2021 main conference. More information in our blog post.


ICML 2021
17 Jul 2021
Seven papers with OATML members accepted to ICML 2021, together with 14 workshop papers. More information in our blog post.

Angelos Filos awarded 2021 J.P. Morgan PhD Fellowship
01 Jun 2021
Angelos Filos is one of the recipients of the 2021 J.P. Morgan PhD Fellowship. Congratulations to the winners!

Angelos Filos co-organising NeurIPS 2020 Workshop on Talking to Strangers: Zero-Shot Emergent Communication
13 Oct 2020
OATML DPhil student Angelos Filos is co-organising the NeurIPS 2020 Workshop on Talking to Strangers: Zero-Shot Emergent Communication.

Uncertainty in Brain Tumor Segmentation Challenge
05 Jun 2020
We’re organising the second “Quantification of Uncertainty in Segmentation” task as part of the Multimodal Brain Tumor Segmentation Challenge at MICCAI 2020, together with Angelos Filos, Raghav Mehta and Tal Arbel.
Six group members honoured as NeurIPS top reviewers
07 Sep 2019
Six group members honoured as top reviewers at NeurIPS 2019: 2 members among the top 400 highest scoring reviewers and awarded free registration (Tim G. J. Rudner and Sebastian Farquhar), and 4 among the top 50% reviewers (Zac Kenton, Andreas Kirsch, Angelos Filos and Joost van Amersfoort).
Angelos Filos co-organising NeurIPS 2019 Workshop on Emergent Communication: Towards Natural Language
01 Sep 2019
OATML DPhil student Angelos Filos is co-organising the NeurIPS 2019 Workshop on Emergent Communication: Towards Natural Language.
Uncertainty in Brain Tumor Segmentation Challenge
15 Aug 2019
We’re organising a “Quantification of Uncertainty in Segmentation” task as part of the Multimodal Brain Tumor Segmentation Challenge at MICCAI 2019, together with Angelos Filos, Raghav Mehta and Tal Arbel.
Publications while at OATML:

Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these... [full abstract]
Neil Band, Tim G. J. Rudner, Qixuan Feng, Angelos Filos, Zachary Nado, Michael W. Dusenberry, Ghassen Jerfel, Dustin Tran, Yarin Gal
NeurIPS Datasets and Benchmarks Track, 2021
Spotlight Talk, NeurIPS Workshop on Distribution Shifts, 2021
Symposium on Machine Learning for Health (ML4H) Extended Abstract Track, 2021
NeurIPS Workshop on Bayesian Deep Learning, 2021
[OpenReview] [Code] [BibTex]

Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Addi... [full abstract]
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jasper Snoek, Yarin Gal, Dustin Tran
NeurIPS Workshop on Bayesian Deep Learning, 2021
[arXiv] [Code] [Blog Post (Google AI)] [BibTex]

Self-Consistent Models and Values
Learned models of the environment provide reinforcement learning (RL) agents with flexible ways of making predictions about the environment. In particular, models enable planning, i.e. using more computation to improve value functions or policies, without requiring additional environment interactions. In this work, we investigate a way of augmenting model-based RL, by additionally encouraging a learned model and value function to be jointly _self-consistent_. Our approach differs from classic planning methods such as Dyna, which only update values to be consistent with the model. We propose multiple self-consistency updates, evaluate these in both tabular and function approximation settings, and find that, with appropriate choices, self-consistency helps both policy evaluation and control.
Gregory Farquhar, Kate Baumli, Zita Marinho, Angelos Filos, Matteo Hessel, Hado van Hasselt, David Silver
NeurIPS, 2021
[Paper]

PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
We study reinforcement learning (RL) with no-reward demonstrations, a setting in which an RL agent has access to additional data from the interaction of other agents with the same environment. However, it has no access to the rewards or goals of these agents, and their objectives and levels of expertise may vary widely. These assumptions are common in multi-agent settings, such as autonomous driving. To effectively use this data, we turn to the framework of successor features. This allows us to disentangle shared features and dynamics of the environment from agent-specific rewards and policies. We propose a multi-task inverse reinforcement learning (IRL) algorithm, called _inverse temporal difference learning_ (ITD), that learns shared state features, alongside per-agent successor features and preference vectors, purely from demonstrations without reward labels. We further show how to seamlessly integrate ITD with learning from online environment interactions, arriving at a novel a... [full abstract]
Angelos Filos, Clare Lyle, Yarin Gal, Sergey Levine, Natasha Jaques, Gregory Farquhar
ICML, 2021 (long talk)
[Paper]

Invariant Causal Prediction for Block MDPs
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give e... [full abstract]
Amy Zhang, Clare Lyle, Shagun Sodhani, Angelos Filos, Marta Kwiatkowska, Joelle Pineau, Yarin Gal, Doina Precup
Causal Learning for Decision Making Workshop at ICLR, 2020
[Paper]
ICML, 2020
[Paper]

Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
Out-of-training-distribution (OOD) scenarios are a common challenge of learning agents at deployment, typically leading to arbitrary deductions and poorly-informed decisions. In principle, detection of and adaptation to OOD scenes can mitigate their adverse effects. In this paper, we highlight the limitations of current approaches to novel driving scenes and propose an epistemic uncertainty-aware planning method, called _robust imitative planning_ (RIP). Our method can detect and recover from some distribution shifts, reducing the overconfident and catastrophic extrapolations in OOD scenes. If the model's uncertainty is too great to suggest a safe course of action, the model can instead query the expert driver for feedback, enabling sample-efficient online adaptation, a variant of our method we term _adaptive robust imitative planning_ (AdaRIP). Our methods outperform current state-of-the-art approaches in the nuScenes _prediction_ challenge, but since no benchmark evaluating OOD d... [full abstract]
Angelos Filos, Panagiotis Tigas, Rowan McAllister, Nicholas Rhinehart, Sergey Levine, Yarin Gal
ICML, 2020
[Paper] [Code] [Website]

Uncertainty Evaluation Metric for Brain Tumour Segmentation
In this paper, we develop a metric designed to assess and rank uncertainty measures for the task of brain tumour sub-tissue segmentation in the BraTS 2019 sub-challenge on uncertainty quantification. The metric is designed to: (1) reward uncertainty measures where high confidence is assigned to correct assertions, and where incorrect assertions are assigned low confidence and (2) penalize measures that have higher percentages of under-confident correct assertions. Here, the workings of the components of the metric are explored based on a number of popular uncertainty measures evaluated on the BraTS 2019 dataset.
Raghav Mehta, Angelos Filos, Yarin Gal, Tal Arbel
MIDL, 2020
[Paper]

Robust Imitative Planning: Planning from Demonstrations Under Uncertainty
Learning from expert demonstrations is an attractive framework for sequential decision-making in safety-critical domains such as autonomous driving, where trial and error learning has no safety guarantees during training. However, naïve use of imitation learning can fail by extrapolating incorrectly to unfamiliar situations, resulting in arbitrary model outputs and dangerous outcomes. This is especially true for high capacity parametric models such as deep neural networks, for processing high-dimensional observations from cameras or LIDAR. Instead, we model expert behaviour with a model able to capture uncertainty about previously unseen scenarios, as well as inherent stochasticity in expert demonstrations. We propose a framework for planning under epistemic uncertainty and also provide a practical realisation, called robust imitative planning (RIP), using an ensemble of deep neural density estimators. We demonstrate online robustness to out-of-training distribution scenarios on th... [full abstract]
Panagiotis Tigas, Angelos Filos, Rowan McAllister, Nicholas Rhinehart, Sergey Levine, Yarin Gal
NeurIPS2019 Workshop on Machine Learning for Autonomous Driving
[Paper]

Improving MFVI in Bayesian Neural Networks with Empirical Bayes: a Study with Diabetic Retinopathy Diagnosis
Specifying meaningful weight priors for variational inference in Bayesian deep neural network (DNN) is a challenging problem, particularly for scaling to larger models involving high dimensional weight space. We evaluate the recently proposed, MOdel Priors with Empirical Bayes using DNN (MOPED) method for Bayesian DNNs within the Bayesian Deep Learning (BDL) benchmarking framework. MOPED enables scalable VI in large models by providing a way to choose informed prior and approximate posterior distributions for Bayesian neural network weights using Empirical Bayes framework. We benchmark MOPED with mean field variational inference on a real-world diabetic retinopathy diagnosis task and compare with state-of-the-art BDL techniques. We demonstrate MOPED method provides reliable uncertainty estimates while outperforming state-of-the-art methods, offering a new strong baseline for the BDL community to compare on complex real-world tasks involving larger models.
Ranganath Krishnan, Mahesh Subedar, Omesh Tickoo, Angelos Filos, Yarin Gal
Workshop on Bayesian Deep Learning, NeurIPS 2019
[Paper]

A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give 'better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on diabetic retinopathy diagnosis. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-... [full abstract]
Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Arnoud de Kroon, Yarin Gal
Spotlight talk, NeurIPS Workshop on Bayesian Deep Learning, 2019
[Preprint] [Code] [BibTex]

Towards Inverse Reinforcement Learning for Limit Order Book Dynamics
We investigate whether Inverse Reinforcement Learning (IRL) can infer rewards from agents within real financial stochastic environments: limit order books (LOB). Our results illustrate that complex behaviours, induced by non-linear reward functions amid agent-based stochastic scenarios, can be deduced through inference, encouraging the use of inverse reinforcement learning for opponent-modelling in multi-agent systems.
Jacobo Roa-Vicens, Cyrine Chtourou, Angelos Filos, Francisco Rullan, Yarin Gal, Ricardo Silva
Oral Presentation, Multi-Agent Learning Workshop at the 36th International Conference on Machine Learning, 2019
[arXiv] [BibTex]

Generalizing from a few environments in safety-critical reinforcement learning
Before deploying autonomous agents in the real world, we need to be confident they will perform safely in novel situations. Ideally, we would expose agents to a very wide range of situations during training (e.g. many simulated environments), allowing them to learn about every possible danger. But this is often impractical: simulations may fail to capture the full range of situations and may differ subtly from reality. This paper investigates generalizing from a limited number of training environments in deep reinforcement learning. Our experiments test whether agents can perform safely in novel environments, given varying numbers of environments at train time. Using a gridworld setting, we find that standard deep RL agents do not reliably avoid catastrophes on unseen environments – even after performing near optimally on 1000 training environments. However, we show that catastrophes can be significantly reduced (but not eliminated) with simple modifications, including Q-network en... [full abstract]
Zac Kenton, Angelos Filos, Owain Evans, Yarin Gal
ICLR 2019 Workshop on Safe Machine Learning
[paper]
Reproducibility and Code

OATomobile: A research framework for autonomous driving
OATomobile is a library for autonomous driving research. OATomobile strives to expose simple, efficient, well-tuned and readable agents, that serve both as reference implementations of popular algorithms and as strong baselines, while still providing enough flexibility to do novel research.
CodeAngelos Filos, Panagiotis Tigas

Code for Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints.
CodeAngelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal
Blog Posts

13 OATML Conference papers at NeurIPS 2021
OATML group members and collaborators are proud to present 13 papers at NeurIPS 2021 main conference. …
Full post...Jannik Kossen, Neil Band, Aidan Gomez, Clare Lyle, Tim G. J. Rudner, Yarin Gal, Binxin (Robin) Ru, Clare Lyle, Lisa Schut, Atılım Güneş Baydin, Tim G. J. Rudner, Andrew Jesson, Panagiotis Tigas, Joost van Amersfoort, Andreas Kirsch, Pascal Notin, Angelos Filos, 11 Oct 2021

21 OATML Conference and Workshop papers at ICML 2021
OATML group members and collaborators are proud to present 21 papers at ICML 2021, including 7 papers at the main conference and 14 papers at various workshops. Group members will also be giving invited talks and participate in panel discussions at the workshops. …
Full post...Angelos Filos, Clare Lyle, Jannik Kossen, Sebastian Farquhar, Tom Rainforth, Andrew Jesson, Sören Mindermann, Tim G. J. Rudner, Oscar Key, Binxin (Robin) Ru, Pascal Notin, Panagiotis Tigas, Andreas Kirsch, Jishnu Mukhoti, Joost van Amersfoort, Lisa Schut, Muhammed Razzak, Aidan Gomez, Jan Brauner, Yarin Gal, 17 Jul 2021
22 OATML Conference and Workshop papers at NeurIPS 2020
OATML group members and collaborators are proud to be presenting 22 papers at NeurIPS 2020. Group members are also co-organising various events around NeurIPS, including workshops, the NeurIPS Meet-Up on Bayesian Deep Learning and socials. …
Full post...Muhammed Razzak, Panagiotis Tigas, Angelos Filos, Atılım Güneş Baydin, Andrew Jesson, Andreas Kirsch, Clare Lyle, Freddie Kalaitzis, Jan Brauner, Jishnu Mukhoti, Lewis Smith, Lisa Schut, Mizu Nishikawa-Toomey, Oscar Key, Binxin (Robin) Ru, Sebastian Farquhar, Sören Mindermann, Tim G. J. Rudner, Yarin Gal, 04 Dec 2020
13 OATML Conference and Workshop papers at ICML 2020
We are glad to share the following 13 papers by OATML authors and collaborators to be presented at this ICML conference and workshops …
Full post...Angelos Filos, Sebastian Farquhar, Tim G. J. Rudner, Lewis Smith, Lisa Schut, Tom Rainforth, Panagiotis Tigas, Pascal Notin, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Jishnu Mukhoti, Yarin Gal, 10 Jul 2020

Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
In autonomous driving, we generally train models on diverse data to maximize the coverage of possible situations the vehicle may encounter at deployment. Global data coverage would be ideal, but impossible to collect, necessitating methods that can generalize safely to new scenarios. As human drivers, we do not need to re-learn how to drive in every city, even though every city is unique. Hence, we’d like a system trained in Pittsburgh and Los Angeles to also be safe when deployed in New York, where the landscape and behaviours of the drivers is different. …
Full post...Angelos Filos, Panagiotis Tigas, Rowan McAllister, Nicholas Rhinehart, Sergey Levine, Yarin Gal, 09 Jul 2020

25 OATML Conference and Workshop papers at NeurIPS 2019
We are glad to share the following 25 papers by OATML authors and collaborators to be presented at this NeurIPS conference and workshops. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Tom Rainforth, Panagiotis Tigas, Andreas Kirsch, Clare Lyle, Joost van Amersfoort, Yarin Gal, 08 Dec 2019

Poor generalization can be dangerous in RL!
We want to develop reinforcement learning (RL) agents that can be trusted to act in high-stakes situations in the real world. That means we need to generalize about common dangers that we might have experienced before, but in an unseen setting. For example, we know it is dangerous to touch a hot oven, even if it’s in a room we haven’t been in before. …
Full post...Zac Kenton, Angelos Filos, Yarin Gal, 02 Jul 2019
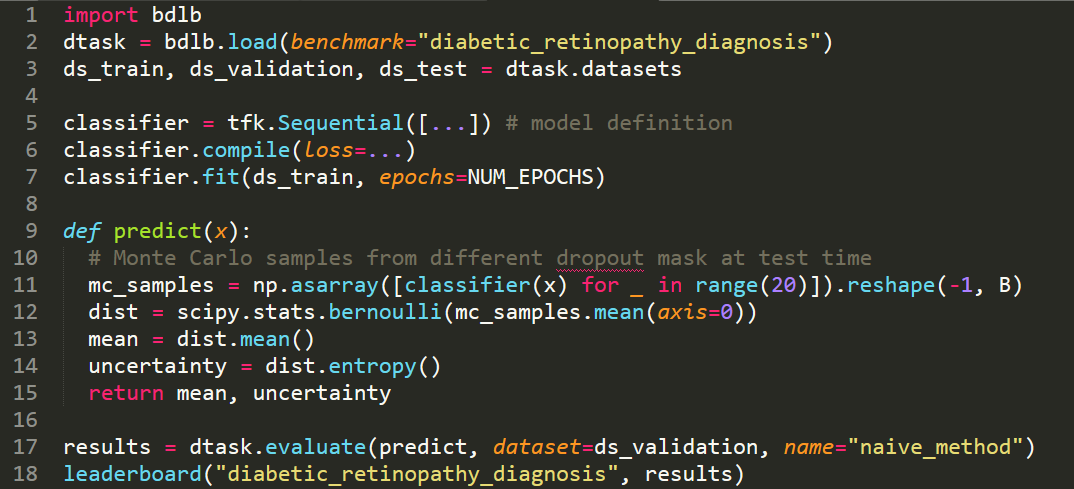
Bayesian Deep Learning Benchmarks
In order to make real-world difference with Bayesian Deep Learning (BDL) tools, the tools must scale to real-world settings. And for that we, the research community, must be able to evaluate our inference tools (and iterate quickly) with real-world benchmark tasks. We should be able to do this without necessarily worrying about application-specific domain knowledge, like the expertise often required in medical applications for example. We require benchmarks to test for inference robustness, performance, and accuracy, in addition to cost and effort of development. These benchmarks should be at a variety of scales, ranging from toy MNIST-scale benchmarks for fast development cycles, to large data benchmarks which are truthful to real-world applications, capturing their constraints. …
Full post...Angelos Filos, Sebastian Farquhar, Aidan Gomez, Tim G. J. Rudner, Zac Kenton, Lewis Smith, Milad Alizadeh, Yarin Gal, 14 Jun 2019