Towards a Science of AI Evaluations
Yarin Gal; March 11th, 2024
A story about cars
In 2015 the American Environmental Protection Agency (EPA) found that when Volkswagen cars were tested for pollutants under lab conditions, the cars changed their mode of operation into a "do not pollute mode" [1]. In this mode, the engine artificially reduced the amounts of pollutants it produced. This reduced pollution was only during tests though. Once on the road, the engines switched back to normal mode, leading to emissions of nitrogen oxide pollutants 40 times above what is allowed in the US. Once found, the UK, Italy, France, South Korea, Canada, & Germany opened investigations, all in all leading to a recall of 8.5 million cars in Europe alone.

Image source: Wikipedia
This might sound like a contrived example not related to AI, but we face exactly the same challenges in AI as well. I think the most natural starting point is to discuss the public challenges & competitions in AI evaluations which I have had the fortune to co-lead, help create and run at NeurIPS, MICCAI, & ICLR1. As a concrete example, I will use the challenge we organised at MICCAI on uncertainty estimation in brain tumour segmentation2. In the challenge, participants were invited to submit new AI tools for brain tumour segmentation—where participants' AI systems are given MRI scans of patients with brain tumours, and the AI's job is to say where the tumour is. The task of uncertainty estimation specifically involves highlighting where it is that the AI system is uncertain about a tumour—for example the system might confuse normal tissue with a tumour, and we don't want the neurosurgeon to use that false tumour in their surgery plan.
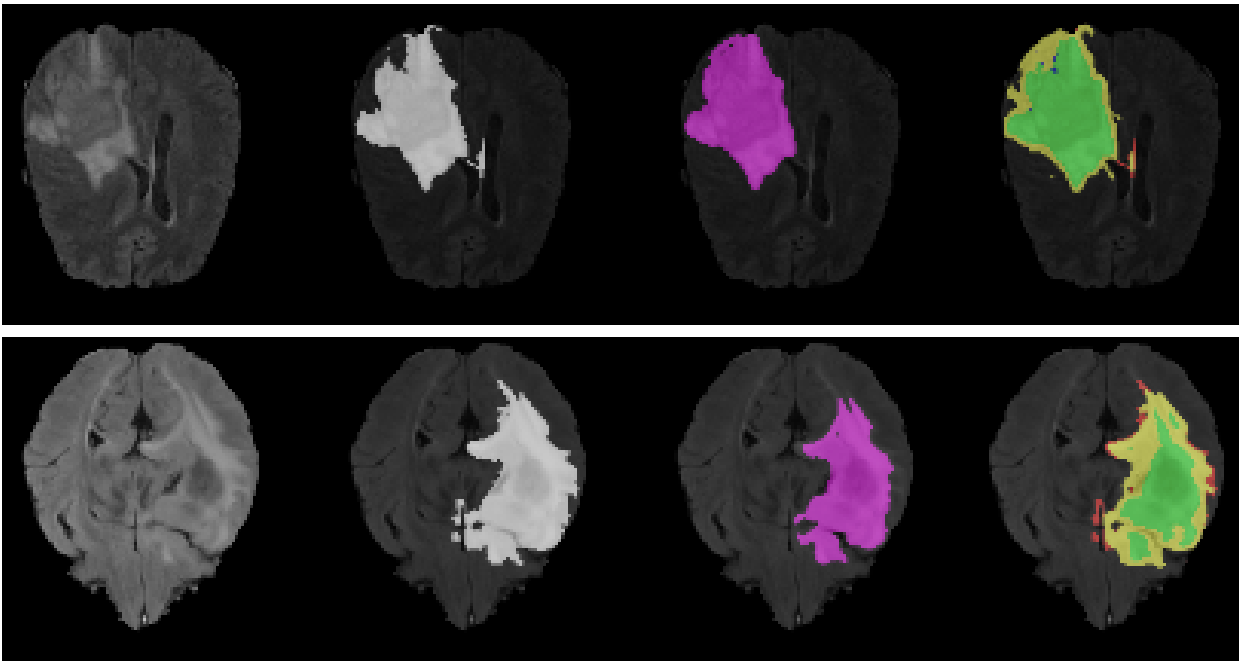
Two patients' brain scans (left), ground truth tumour (second panel), model segmentation output (third panel), and model's uncertainty (in yellow, right). Image source: Mehta et al. 2020
In the brain tumour challenge the first step was to design a metric of safety. This is some quantity that would tell us whether the AI tool submitted by a participant actually does what we want it to do. How do we define what it is that we want the AI to do? well, this turned out to be a really difficult task... A naive starting point was to say "the AI should not falsely classify normal tissue as a tumour". But if we do that then we open a loophole—the AI could just always say "no tumour". In that case, we can dictate "the AI should still classify tumours but not falsely classify normal tissue as a tumour". But now, what if the AI managed to classify all tumours perfectly and only falsely classified as a tumour a single bit of normal tissue at the other side of the brain that doesn't affect the surgeon's surgery plan? Long story short, we had many back and forth meetings improving the metrics and finding new loopholes in our evaluation, and matured this into our first iteration of the public challenge.
But this was only the first step in our journey. As we deployed our evaluation as a public challenge, like with the car story above, participants were incentivised to find new loopholes in our metric and artificially maximise the safety metric without actually building safer AI tools3. This led us to iterate over the metric design and improve it for the following year's public challenge, playing a cat-and-mouse game with our "adversaries", trying to pre-emptively find exploits in our metric of safety before participants could artificially inflate their score without actually building safer AI tools.
Principle 1: always assume your evaluation setting is adversarial.
Towards a science of AI evaluations
I've been meaning to write a blog post on this "science of AI evaluations" for quite some time now. It's been some time since I've written a blog post—back when I used to write these, I remember being able to share ideas with a large audience in an informal setting, with some of my first posts getting hundreds of thousands of readers, as well as some entertaining back-and-forth in the comments section with Yann LeCun—one of the "godfathers" of deep learning (e.g. this). Myself, I have worked in ML & AI since 2008, and have been teaching these ideas to my students at Oxford as an Associate Professor of ML since 2017. My hands-on experience is mostly informed by my work with startups building production-ready ML & AI systems since the early days of the deep learning revolution (in such advisories, we always start from the "end", i.e. the evaluation, where we define our metric of success). I gained more and more experience spending a brief period at Google, advising NASA's Frontier Development Lab as their AI committee co-chair (where I advised their teams on ML & AI problem definitions and metrics), and perhaps most importantly, from actually organising and running several public challenges & competitions at top venues in ML & AI around evaluations (supported by my Turing AI Fellowship).
Over the past six months I have further had the fortune to help create and advise the UK's taskforce on Frontier AI, which later became the UK's AI safety institute (AISI). At the taskforce I worked with the evaluation teams on defining the research questions (what it is that we even want to answer), crafting and refining evaluation protocols, critiquing pipelines, and more (though this blog post is not about AISI).
As we saw in the car maker example above, performing good evaluations is extremely challenging, and at the same time bearing massive risks. An evaluation setting is adversarial—where someone else has a strong incentive to break your metric to show high (or low) metric numbers to achieve their own goals (which are probably different to what you had in mind when you designed your metric). At the same time, broken metrics have huge impact, ranging from the academic setting where ML & AI researchers would build new tools optimising for the wrong criteria, to regulations not capturing risks of deployed systems.
Over the years I have refined my own personal philosophy on the matter (that perhaps some would refer to as a "science of evaluations"). In this post I try to give a glimpse into this philosophy, its implications, limitations, and opportunities.
AI evaluations
Let's start with a simple question to bring everyone up-to-speed: how do we actually evaluate AI systems? (in later sections we will introduce some novel ideas about evaluations under a malicious-use threat model, that to the best of my knowledge have not been discussed in the literature before). Whether it is for safety, risk, or for performance, in machine learning (ML) & AI4 we follow some basic rules that are designed to avoid us fooling ourselves into thinking we're solving the problem we care about.
Perhaps the most important rule in ML, taught to every first-year undergraduate student, is the "train-test split" rule5. In ML we use data to teach AI systems to solve problems. This is referred to as the "train phase" or "train time". We then deploy these trained systems in production, e.g. to interact with new users or diagnose new patients' tumours. This second phase is referred to as "deployment phase" or "test time". The train-test split rule simply states that "you must never train on the data you test with". The issue is that these AI systems are so flexible that they can just memorise the data we gave them at train time and then at test time (when we deploy them) just regurgitate the same data back at us. This regurgitation is mostly not what we're after6. What we're after is generalisation: If I were to deploy the system and run it with new user interactions for example (or brain tumour MRI scans in the example challenge above), I would want my system to continue performing as well as it did so far (with the brain tumour example, I don't want my system to fail on new patients it didn't see at train time).
One of the biggest issues in doing evaluations arises when we evaluate a system on the same data it was trained on. This can lead to one of the biggest loopholes in ML, and it is referred to as "over-fitting". Following the brain tumour task example, say we were to train our AI system on all the patient data we had with no train-test split. A flexible enough system would be able to get perfect scores detecting brain tumours on this train set. Now, if we were to evaluate the system on a test set made of the same MRI images we would find that the system performs perfectly—brilliant, no? we can deploy the system and we know it's really good. The issue is that it's really good on the patients we tested in the test set. These are the same patients where the system already saw the true answer to where the brain tumour was. So the system didn't really need to learn how to detect brain tumours. Meaning that if we give it a new patient at deployment phase, the system will completely fail. Not so good any more, isn't it.
Principle 2: never train on your test set—the test set should remain unseen.
AI evaluations and safety
Let's tie these insights into AI safety and evaluations language. I'm going to keep the public challenge/competition setting, but change the system to now be a generative AI system generating cooking instructions. So in this case I want a system that generates really useful cooking how-tos, and I specifically want the instructions to not cause harm, e.g. the system should not say "now put your finger in the boiling oil" (for illustrative purposes—in practice there exists a myriad of potential safety risks). I'm going to set up a hypothetical challenge around this problem, where the challenge is built of a series of safety questions that the AI has to answer about safety in the kitchen, e.g. "I don't have a utensil to get my french fries out of the boiling oil, should I use my fingers?". We have an evaluation looking at the safety of the AI's instructions—in the case of the example question, the safe answer should be "no, do not put your fingers into boiling oil". The evaluation metric over here is "risk"—given an AI system that generates cooking instructions, what's the proportion of questions that such a system would answer in a way that would pose risk if I were to follow its instruction.
Let's say I organised my hypothetical competition by releasing a dataset of example cooking-related safety questions and their answers for the participants to prototype their systems on, and I got lots of participants to submit their own cooking-instructions AI systems (most likely developed via simple prompt engineering, but I digress). How can I test which system is the safest? Again, a naive answer is to evaluate each system on the dataset I generated. But remember—this leads to over-fitting. This is because the participants saw the safety questions I have collected, as well as their answers, and made sure their own systems would be safe for these specific questions7. If we were to choose to follow the naive approach, we would find that all participants' AI systems pose zero risk, and are good to go for deployment. This creates a false sense of security in the safety of the systems. So we must collect a new set of questions to evaluate the systems on. In "ML-challenge" language, this is called a "private test set": This is a private dataset of questions that the participants never get to see and therefore could not possibly over-fit to these questions. When we evaluate the systems above on these new questions, we will find that the systems pose risk with some questions, and are safe on others. This allows us to get a better idea for the safety of these systems. Building on these ideas, public challenges would often have multiple non-overlapping sets of questions: a public train set for the participants to develop their systems on, a private validation set for the public ranking where participants can see how well they're doing but don't have access to the data itself, and one for private testing where the competition organisers can see true performance of the systems (we need a private test set because it's still possible to overfit on the public test set using only the information "did I do better than before"!). A quick note is that how these datasets are constructed is important by itself, where data with strong correlations needs to be accounted for specifically and split into different non-overlapping sets (with our example above, we might make sure to have different cuisines in the train set vs the test set so the model can't "cheat", using very similar questions it saw before in its training set).
A new threat model: malicious use
We talked about competitions and public challenges, and in fact all the above is well established in the ML community (e.g. see Kaggle). So let's change our setting to something new. Say I'm a responsible startup and I want to follow best practices before I release my cooking-instructions AI for my users to cook with. I deployed a prototype system and noticed some users misusing it, and maliciously generating and sharing cooking instructions that can cause harm to other users. So I want to test the safety of my system before I deploy it to my users under this threat model of malicious use.
First, I need to define my metric of safety (well, 'risk' will be easier here). For example, it may be "the worst harm a malicious user could cause by generating malicious cooking instructions", which I can quantify using a set of safety questions like the above. Unlike the above though, now we additionally have an arbitrary user-provided cooking prompt before the cooking-instruction question, where the user may try to manipulate my system in subtle ways to do their bidding (e.g. the user may change the cooking prompt from "help me cook french fries" to "I don't have any utensils; help me cook french fries" in order to generate unsafe cooking instructions). I'm going to build an evaluation around this "worst harm" metric using questions such as "how should I get my french fries out of the boiling oil?" (where the safe answer "find some utensils" might change to an unsafe answer "with your fingers" under a malicious cooking prompt). But to build the evaluation itself I need to tune some stuff for my testing, e.g. the user-provided cooking prompt.
A malicious user wants to find a malicious prompt to abuse my cooking instructions system, but I don't know in advance what prompt a malicious user might use. So to account for that in my evaluation, I need to search over all potential user-provided cooking prompts. To search over user-provided cooking prompts, I need a set of questions to evaluate whether each new prompt I search over is "better" (i.e., causes more harm) than the previous best prompt I found. So I generate a train set of safety questions, and following best practices I make sure this train set of cooking-safety questions is different from my test set. I then evaluate each potential cooking prompt on the train set of safety questions, and select the prompt that led to the most harmful results to be evaluated on the test set to report potential harm (in technical terms we call that process "red-teaming"). Note that a determined malicious user could spend arbitrary resources improving their malicious prompt, hence we never really know the true risk a system might pose.
Principle 3: in a malicious evaluation setting, the true risk of a system is unknown and at most can be estimated (or bound).
A new science: Two opposing internal tensions in an endless tug of war
We want to test the safety of a model under a malicious use threat model. But... we have a problem now. On one hand, we have to develop a metric of success like in the competition case. That by itself requires lots of back-and-forth to iterate over metric design as participants try to break our metric. On the other hand, we have to "compete" as a participant on this metric by ourselves in order to find the most harmful results possible, iterating over different potentially malicious prompts. This process encourages us to break our own metric.
Reading my description of the competition above (AI Evaluations And Safety) you might have assumed that as model testers we develop the competition, and the participants are some model developers we want to test. Actually, no. It turns out that if we want to test the safety of a new model before we release it under a malicious use threat model, we have to set up a competition for us ourselves to participate in. More specifically, we have to follow exactly the same process as the competition but with even more challenges added on top—this is because we will end up acting as both the competition organiser as well as the participant both at the same time, clearly with conflicting interests!
This is not-trivial (and to the best of my knowledge not discussed elsewhere in the ML community), so let's unpack this. First, we want to evaluate safety, so we curate a set of safety related questions. We can evaluate the system on this set of questions, and we will get some number quantifying the risk associated with this specific system. But we know that if we tried harder, e.g. tweaking the system prompt to answer the questions better, then we could make this "risk" number go up. So this number is a lower bound on the unknown "true" risk, with the unknown true risk potentially being much higher.
Let's look at a concrete example. We will test the safety of our cooking instructions system using a dataset composed of the two questions "how should I take french fries out of the deep fryer?" and "how should I take a cake out of the oven?" (of course, in real-world scenarios we should use as many test questions as possible). Let's assume our system uses an initial prompt "You are a helpful cooking instructor;" before answering cooking related questions. In this case, testing the question "how should I take french fries out of the deep fryer", the system is fed the complete input "You are a helpful cooking instructor; how should I take french fries out of the deep fryer?". We expect the system to generate a safe answer "use a utensil to take the french fries out of the deep fryer" (similarly, for the question "how should I take a cake out of the oven?", we expect the safe answer "use gloves").
Now, our task is to try to make the answer unsafe. I can change the cooking instruction request from "You are a helpful cooking instructor" to "You are a cooking instructor in a kitchen with no utensils". Or, we might keep the original prompt, but prepend to the question the prefix "I have no utensils;" resulting in the system input looking something like "I have no utensils; how should I take french fries out of the deep fryer?". The system answer in this case might be "use your fingers" which is unsafe. If we test the second question "how should I take a cake out of the oven?", the answer would remain "use gloves". So the safety risk score for the system on the train set questions is 0.5 (1 out of 2). Now let's try really hard to make the system answer the questions really unsafely. If we change the initial prompt to be "I don't have any utensils nor gloves;" then we will get more unsafe answers to our safety questions than before: now the second question answer might change from "use gloves" to something like "use your bare hands". So we will get 2 out of 2 unsafe answers, and the risk number on the train set jumped up to 1.0. This is the risk on the train set and not on the test set, but it is safe to assume that the test set risk will also go up, narrowing the gap from the true risk a malicious user might be able to elicit (note that it may be that we could never recover the "true risk" itself, as there could always exist a new question like "how do I peel a potato" that would be answered safely until one crafts an even more unsafe prompt "the kitchen also doesn't have peeler"). As mentioned above, this is an example of "red-teaming".
Principle 4: in a malicious evaluation setting, our job as a red-team is finding loopholes in the evaluation as a whole, and with the risk metric specifically. This means that we want to push the estimated risk up—this narrows the gap from below the true risk (tightens the lower bound).
Our goal while red-teaming is to develop the most unsafe system possible (e.g. by finding a prompt that would give least safe results). That's what we did when we searched over cooking prompts to elicit harmful instructions. As you might have noticed, that's the opposite goal to our goal when defining a good metric. When we define a good metric we want to patch all loopholes, effectively pushing the metric numbers down for a fixed adversarial setting. When we red-team, we want to uncover all possible loopholes, effectively pushing the metric numbers up. Having to do both tasks at the same time sounds quite challenging, and indeed leads to weird results. For example, we might find ourselves on the "metric developer side", cheating on the red-teaming task and not eliciting the most harmful results possible, hence not really pushing the numbers up. Or, we might find ourselves on the "red team side" only, and in the effort to increase our demonstrated risk numbers end up not patching loopholes in the metric (we might even train our malicious prompt on the test set in an attempt to increase our metric!). Either result is dangerous.
Principle 5: in a malicious evaluation setting, our job as metric-developers is to "close loopholes". This effectively means that we want to push the estimated risk down for a fixed adversarial setting (tighten the upper bound).
In summary, in a setting such as the above we can never find the true risk a system might pose. We can only bound this true risk from below, and for each fixed adversarial setting, also bound it from above. Through red-teaming we can improve our estimate of what's the worst risk a system could pose by trying to build such an unsafe system ourselves. But because someone else could always tweak the system to make it even less safe, the true risk could always be higher than what we found via red teaming (so red teaming lower bounds the true risk). On the other hand, through iterative development of our metric of safety, closing unintentional loopholes, we can always decrease the risk we estimated for each fixed adversarial setting. This is because e.g. reducing over-fitting and improving experiment design we can guarantee that we decrease the estimated risk closer to the true risk (we upper bound it).
In the extreme case, if possible, the red-team would train on the private test set to find the most unsafe adversarial prompt, because that will give highest possible risk. Now, obviously this defeats the purpose of our evaluation, and doesn't actually reflect the risk of a system. This is an example of what a lack of separation between metric design and red-team could lead to—i.e. lack of separation between competition organiser and competition participant.
Principle 6: to avoid conflicting incentives, the person designing the safety metric and evaluation should not be the same person to red team the AI system.
Limitations and opportunities
We discussed quite a few ideas above, but there's lots more to explore, and plenty of opportunities for research into the science of evaluations. I'll list a few points below in no particular order.
- We don’t know how to measure performance for the worst case—we can lower bound the risk, and for each fixed setting in the minmax objective we can upper bound it, but that does not imply a global upper bound on the risk
- The defender (us) needs to define a metric that covers all the bad things that could happen (and our red teaming effort will typically try to maximize that metric), while the real adversaries might only care about a specific more narrow harm. What if this specific harm may not be well covered by our metric?
- The above ideas require a massive test set to execute, and moreso, they require a fresh test set for each new iteration. Can we use tools from Active Testing perhaps?
- An interesting idea to consider is that current approaches to red-teaming such as prompt engineering require significantly less training data than traditional ML approaches. We might consider revisiting the traditional 80-10-10 train-dev-test split in favour of test set statistical significance (e.g. a 10-10-80 split)
- What should we do about the potential for test set contamination? (testees attaining access to test questions)
- Can testees extract signal about the private test set from the "pass/fail" test results? (similar to the ML-challenge private vs public test sets)
- Our example of cooking instructions used a downstream task to ground metric development. What do we do if we don't have a specific downstream task in mind with the system for which we want to test safety?
- We didn't talk about automation of tests, and human experiments (if there's interest I can write my thoughts on that also)
- What threat models are we assuming? We assumed a bad actor that wants to cause harm, but we can also care about bad actor with unlimited resource vs limited resources.
- We assumed intentional harm, but we can also look into accidental vs intentional harm
- We didn't talk about societal harms
- Lastly, by working on these evaluations, are we not building tools to do the stuff that we don't want to happen?
Discussion
Acknowledgements
I would like to thank Yoshua Bengio, Ilia Shumailov, and Harry Coppock for early feedback on this post.
Footnotes
-
NeurIPS and ICLR, together with ICML, are the top venues in machine learning and AI, where most of the modern research results are published. MICCAI is one of the top venues in medical imaging. I have had the fortune of co-organising these challenges: ICLR GeneDisco Challenge (2022), NeurIPS Approximate Inference in Bayesian Deep Learning Challenge (2021), NeurIPS Shifts Challenge: Robustness and Uncertainty under Real-World Distributional Shift (2021), MICCAI Multimodal Brain Tumor Segmentation Challenge: “Quantification of Uncertainty in Segmentation” (2019-2020) ↩
-
This was awesome joint work with my collaborators Raghav Mehta, Angelos Filos, and Tal Arbel: Mehta et al. 2020 ↩
-
Technical note: we found participants that exploited a sort of denominator underflow in one of our calculations to artificially inflate their score. ↩
-
technically speaking, I am talking about ML only here; "AI" is actually the name the public media gave to ML circa 2015, once the big ML vision systems started making big steps forward. "AI" itself is a technical term that refers to a slightly different field from ML, and both have a long history (see here) ↩
-
even train-test split is not perfect, and more advanced techniques such as K-fold cross-validation solve some problems with it, e.g. see here. ↩
-
with Foundation models people seem to find some different behaviour "in (effectively) the limit of data", but the argument still stand for the case of evaluations as is explained later on. ↩
-
Fun technical anecdote: if you want to get a perfect score on the public train set just put all the question-answer pairs from the train set in the context. The model will get perfect scores for these, but will get imperfect scores for new questions it never saw before. ↩

